【真実!】WEBはSEOとクローラーの働きで出来ている!
ネットは便利で検索キーワードを利用すれば、知りたい事が瞬時に画面表示されるというのは大きなメリットと言えるでしょう。
それを語る際に欠かせないのが、SEOとクローラーです。
そこで、この2ワードをキーにして、インターネット検索の裏側を探ってみました。
お目当てのWEBサイトが見つかりやすくなったのは、SEOのお陰
星の数程あるWEBサイトを隅から隅までチェックする事は、時事上不可能と言って良いでしょう。それならば、出来るだけ質の良いWEBサイトのランキングを上げる事により、検索結果画面において、ユーザーにURLリンクを見つけて貰わなければなりません。しかしながら、URLリンクは人間にはわかりづらい表記である為に、一般にはタイトルを見て判断する事になります。このタイトルの付け方も、ランキングに影響する可能性があるのですが、とりあえずはURLリンクを、クリックして貰える確率は高くなったと言って良いでしょう。もし、ECサイトをしているのであれば、ビジネスチャンスは飛躍的に伸びると考えられるのです。以上は、googleのSEO(検索エンジン最適化)アルゴリズムに寄るものです。また、大手と言われるyahooも実は、2007年からgoogleが使用しているアルゴリズムを利用する事になりました。但し、yahoo独自のサービスを反映させているので、その分の差異がある事は認識しておく必要があるでしょう。実際の所はgoogleの検索サイトよりも、yahooの検索サイトからの検索が多いという結果がある様です。しかし結局の所googleのSEOあってこその、現在のインターネットが築かれているという点は、関係者しか知られていない事の様です。
一般的なSEOの解釈?
検索エンジン最適化(けんさくエンジンさいてきか、英: Search Engine Optimization、SEO、サーチ・エンジン・オプティマイゼーション)はある特定の検索エンジンを対象として検索結果でより上位に現れるようにウェブページを書き換えること。または、その技術のこと。
引用元:検索エンジン最適化 – Wikipedia https://ja.wikipedia.org/wiki/%E6%A4%9C%E7%B4%A2%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%B3%E6%9C%80%E9%81%A9%E5%8C%96
コメント:SEOのお陰で良質なデーターを、直ぐに見つけ出す事が出来る様になりました。
WEBサイトのデーター収集の鍵を握るのが、クローラーです!!
クローラーって何?
クローラーという用語を聞くと、水泳競技を思い浮かべるかも知れません。確かに「泳ぐ」という点では間違っていませんが、泳ぐのはプールや海では無く、WorldWideWeb(WWW)という広大なネットワークを泳ぎ回るのです。そして、基本的には辿った先のWEBサイト等の、データーを吸い上げていきます。しかし、Webは余りにも広大過ぎて、直ぐにクローラーに発見されない事もあり得る事です。そうなればビジネス目的の場合には、売上にも影響する可能性が考えられます。そこで、例えば新規にWEB制作をしたという場合には、意図的にgoogle側に知らせるという方法があります。具体的には、GoogleSearchConsole(サーチコンソール)を使用する方法です。このツールは、googleから提供されており無料で利用出来るので、積極的に利用するのが賢明と言えます。しかし何らかの理由で、クローラーに来て欲しくないという要望もあり、その対策も存在しています。
クローラとは、全文検索型サーチエンジンの検索データベースを作成するために、世界中のありとあらゆるWebページを回収するプログラム。全文検索型サーチエンジンでは、Webページの内容をサーチエンジン側のデータベースに保存しておき、検索要求があった時にはそのデータベースを検索して結果をはじき出している。検索ロボットはこのデータベースの内容を充実させたり点検したりするプログラムで、まだデータベースに収録されていないWebページや、更新されたWebページを発見しては内容を回収し、結果をデータベースに反映させている。検索ロボットがページを探し出す手段や、検索の対象とするファイルの種類はさまざまである。検索ロボットによってはテキストファイルやPDFファイル、ExcelやWordなどで作成した文書ファイルも回収していく。このため、適切なアクセス権の設定等を怠ったために企業の機密文書が検索可能になってしまったという事故も見られる。検索ロボットに回収されたくないファイルを指定する手段として、HTMLファイル内に検索を拒否することを明記したメタタグ(METAタグ)を記入したり、Webサーバの公開ディレクトリ最上層にロボットの挙動を指定するファイルを配置するという手法がある。しかし、検索ロボットによってはこのような指定を無視してファイルを回収していくため、機密性の高いファイルはアクセス権を制限するなどの手段で守る必要がある。
引用元:クローラとは|crawler|スパイダー|spider|Webクローラ − 意味 / 定義 / 解説 / 説明 : IT用語辞典 http://e-words.jp/w/%E3%82%AF%E3%83%AD%E3%83%BC%E3%83%A9.html
コメント:クローラーは、WEB界の影の立役者と言っても、過言ではないでしょう。
引用元:クローラーは一つではありません https://junichi-manga.com/mechanism-of-google-search/
コメント:WEB検索エンジンは、幾つものクローラーをWeb上に放ちます。
引用元:クローラーは大忙し https://junichi-manga.com/mechanism-of-google-search/
コメント:この様子をまるで、蜘蛛の巣の様であるという事から、スパイダーと呼ぶ人もいます。
インデックス化され、データーベースに蓄積されます
前述したクローラーが、WEBサイトのデーター収集をすると書きましたが、実はそれだけでは不十分なのです。どういう事かというと、得られたデーターのインデックス化をして、専用データーベースに蓄積する作業があります。とはいえこの作業は自動的に行われるので、特に何もしなくて問題ありません。
インデックスとは検索エンジンに記録されたWebサイトの情報のことです。インデックスには、クローラーが持ち帰えった情報がきれいに整理された上で記録されています。どのWebサイトがどんな情報を持ち、どんな話題を扱っているのかのデータです。これが検索の時に使われます。検索エンジンは、検索の度に、インデックスを参照し、検索に使用されたキーワードと関係するWebサイトをインデックスから見つけて検索結果として表示します。検索の対象になるのは、常にこのインデックスに記録されたWebサイトだけなので、記録がないWebサイトは検索の対象から外れます。対象から外れているWebサイトは、もちろんですが、どんなキーワードで検索してもヒットしません。なので、インデックスされるためにはクローラーに来てもらう必要があります。
引用元:インデックスされる仕組み(クローラーの動き方など) | クロスウォーク http://www.crosswalk-seo.com/2016/03/08/%E3%82%A4%E3%83%B3%E3%83%87%E3%83%83%E3%82%AF%E3%82%B9%E3%81%95%E3%82%8C%E3%82%8B%E4%BB%95%E7%B5%84%E3%81%BF%EF%BC%88%E3%82%AF%E3%83%AD%E3%83%BC%E3%83%A9%E3%83%BC%E3%81%AE%E5%8B%95%E3%81%8D%E6%96%B9/
コメント:この過程がないと、googleはここまで実績を伸ばしてくる事は、出来なかったかも知れません。
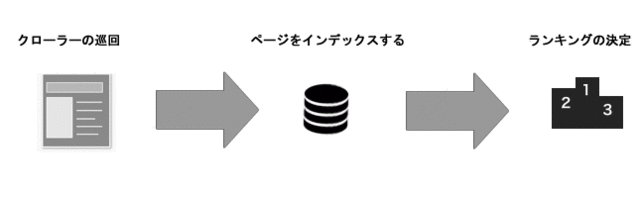
引用元:googleの検査エンジンのイメージ http://www.crosswalk-seo.com/2016/03/08/%E3%82%A4%E3%83%B3%E3%83%87%E3%83%83%E3%82%AF%E3%82%B9%E3%81%95%E3%82%8C%E3%82%8B%E4%BB%95%E7%B5%84%E3%81%BF%EF%BC%88%E3%82%AF%E3%83%AD%E3%83%BC%E3%83%A9%E3%83%BC%E3%81%AE%E5%8B%95%E3%81%8D%E6%96%B9/
コメント:この図を見ると分かる通り、クローラ・インデックス、そしてデーターベースはSEOにとって、不可欠な存在である事がわかります。
クローラーに来て欲しくない場合は、どんなケースが考えられ、またその対策は?
robots.txtを設定しよう
ウェブサイトの規模が大きく、クローラーがサーバーのパフォーマンスに大きく影響している場合には、robots.txtでクロールを制御します。それとともにクロール効率化の為にXMLサイトマップ、rssフィードを設定しておくと良いでしょう。robots.txtはクロールをコントロールする目的のみに使用します。検索結果に表示させない目的では使用する事ができません。その場合はnoindexやベーシック認証を使用しましょう。
引用元:robots.txtの作成と記述方法 使い方と注意点 https://www.allegro-inc.com/seo/robots-txt-setting
コメント:特別に人気のあるサイトで、トラヒックが集中し輻輳しがち等の場合は、robots.txtを適切に設定すれば効果がある筈です。また、会員登録制のサイト等にも、有効に働く様です。
タグの最適化
タグの最適化には幾つかの方法がありますが、ここでは一つだけ紹介します。
meta robotsタグは、robots.txt同様クローラーの制御を行います(実際の効果は異ります)。特に、以下のようにnoindexと記述すると「このページは検索結果に表示しない」という命令になります。よって、このタグを設置したページは検索結果に表示されないことになります。1
引用元:【保存版】あなたのサイトがGoogleにインデックスされない8つの原因 | ホワイトベアー株式会社 http://whitebear-seo.com/cause-of-noindex-in-google/
コメント:タグレベルでも、色々な対策が取れる事がわかりました。